If you have not yet connected the integration with OpenAI, first complete steps 1–3 described in the main instructions.
Assistant is a customizable AI agent built on OpenAI’s technology. It understands the context of a conversation and, depending on which tools are enabled, can pull information from preloaded data. This not only expands the range of useful applications but also improves the quality of OpenAI’s responses.
Table of contents
How does it work?
Let’s take the example of "Service X" to explain how the OpenAI Assistant works.
Internal data: When setting up the assistant, you upload general information about "Service X" — documentation, knowledge base, specifications, and other materials. This data is used to answer common questions about the service and remains unchanged during interactions with users.
For example, the assistant can explain how to register for "Service X", help users understand its main features, or answer frequently asked questions if that information was loaded during setup.
External context: When a customer contacts support with an issue, the assistant not only uses the internal data but also analyzes the customer’s messages using activated tools. This allows it to provide more accurate and relevant responses.
For instance, if a customer reports an authorization error, the assistant reviews the messages, notices a typo in the provided email address, and crafts a response by combining the internal data (preloaded instructions) with the external context (the specific customer message).
Key difference:
Internal data is the information uploaded in advance when setting up the assistant (documentation, knowledge base, specifications, and other materials).
External data is the information the assistant receives during its operation, such as user questions in chat.
Using external data allows the assistant to tailor its responses to the specific situation, while internal data provides the foundational knowledge and overall context.
Example of how it works:
We created a rule for new cases that is triggered in every new case from the Telegram channel and sends a text query [case_description] to the specified assistant. The response received from the assistant is then forwarded to the customer.
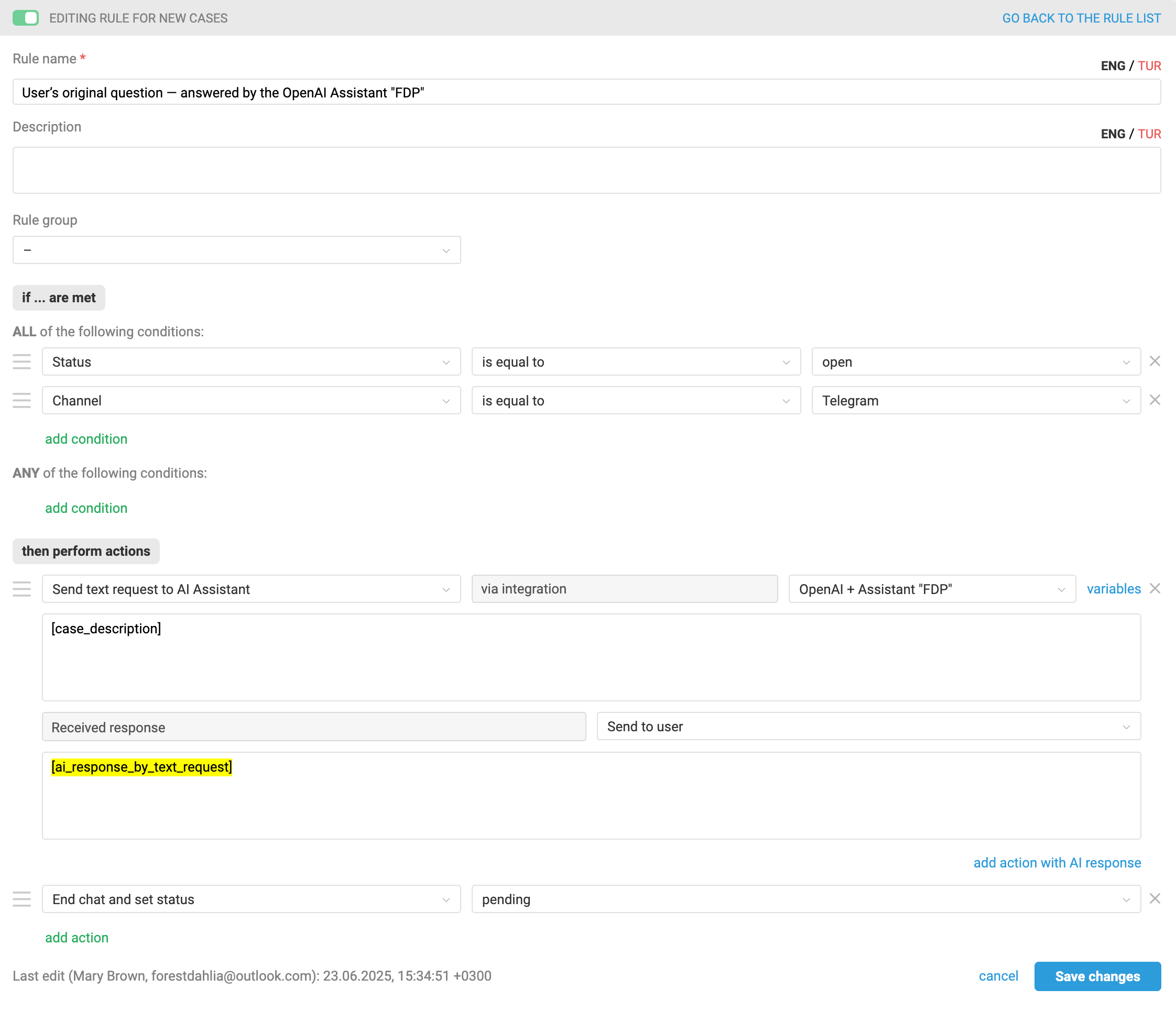
This is how such a rule works:
Creating, configuring, and optimizing the assistant in your OpenAI account is done independently. The Deskie support team does not provide consultation on these matters.
If you don’t have the right specialists on staff or you think setting up the assistant will take them too much time, you can order a paid turnkey setup, which includes:
— creating a personalized assistant in your OpenAI account to handle first-line support tasks;
— uploading internal data (knowledge base, macros, cases from your Deskie account, and other sources), converting it into vector format, and building the assistant’s database;
— three free updates of the assistant’s internal data (by prior request, no more than once a month);
— one-time configuration of rules in your Deskie account to ensure the assistant works correctly according to the algorithm.
The service costs €1000 plus VAT. To order a turnkey assistant setup, please contact us.
Connection
To add Assistant functionality to an existing OpenAI integration, go to your Deskie admin account, navigate to Settings → Integrations, open your OpenAI integration for editing, and enter your Assistant ID.
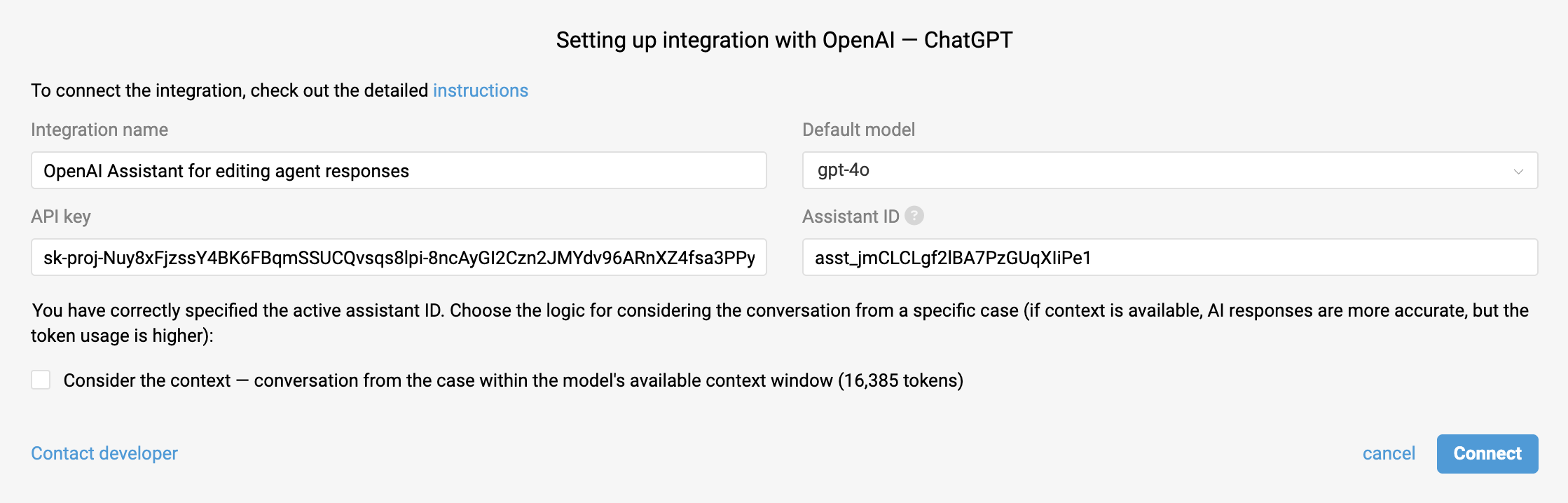
In the "Integration name" field, enter a name that will be easy to recognize later when setting up automation rules.
If the OpenAI integration is not yet set up, first complete steps 1–3 of this instruction.
How to get Assistant ID?
In your OpenAI account, go to Dashboard → Assistants and copy the identifier located under the name of the assistant you plan to use in Deskie.
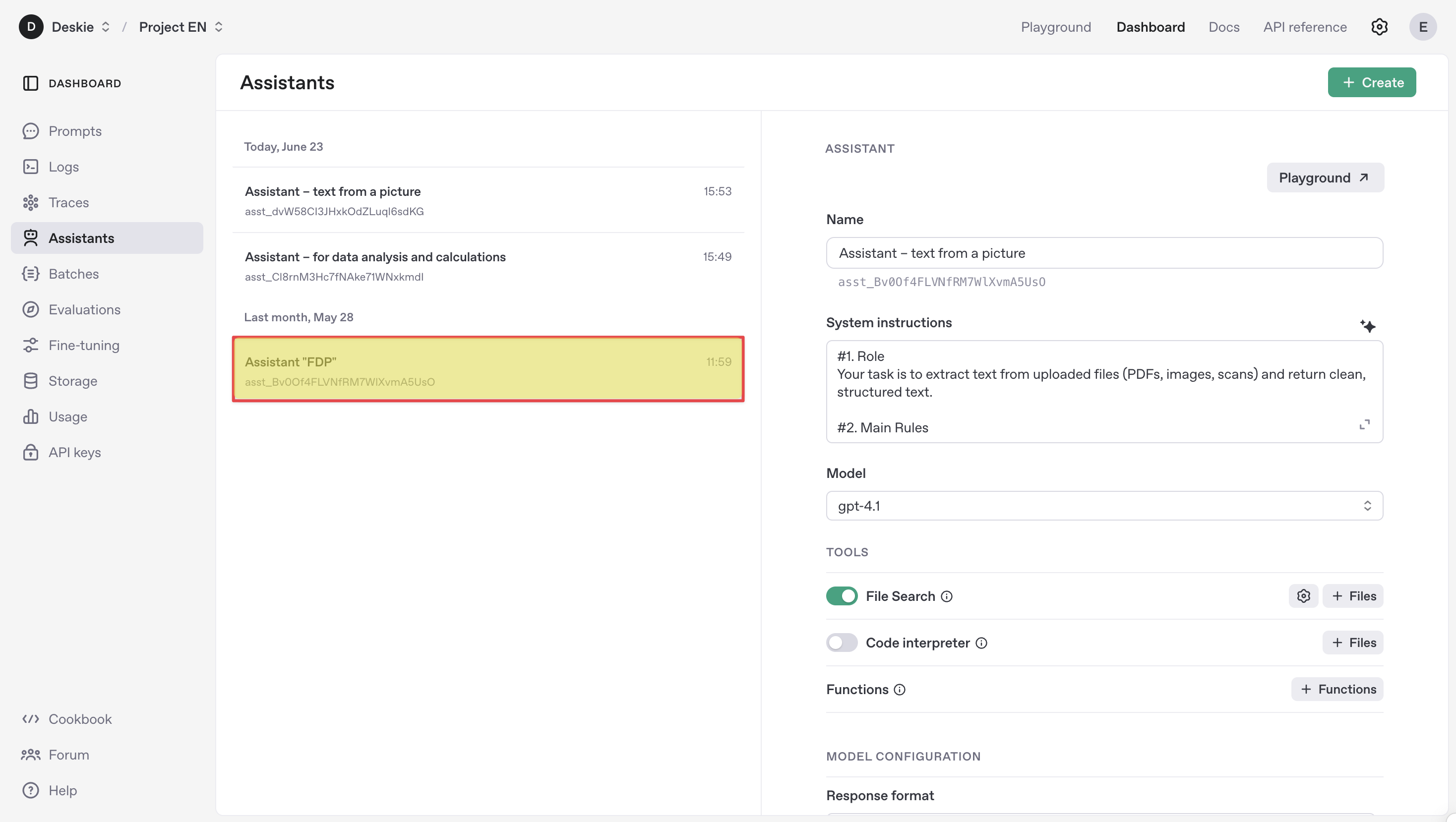
⚠️ For successful validation of the Assistant ID, make sure that the assistant and the API key used to set up the OpenAI integration belong to the same organization and project within OpenAI.
Integration settings
Default model
The assistant will use the model specified in the integration settings to generate responses.
Response quality may suffer if the model set in the integration does not match the model chosen when creating the assistant or the one used to test it in the OpenAI Playground.
For example, if your assistant in the Assistants API was created using GPT-4-turbo, but in Deskie you selected GPT-3.5-turbo, logic errors may occur because the instructions were designed for a more powerful model.
In the OpenAI Playground test environment, you can switch models on the fly. If your goal is to replicate the assistant’s performance in the Playground as closely as possible within Deskie, specify the model in the settings that showed the best results during testing.
💰 When choosing a model, take into account the cost per request — it varies for each model.
⚠️ Fine-tuned models should not be used with the Assistants API. Therefore, this functionality is not supported.
Context
The checkbox "Consider the context..." allows you to choose whether the assistant should take context into account when preparing a response.
💰 By enabling this setting, you improve the quality of OpenAI’s responses, but at the same time increase the cost per request, since more tokens will be consumed.
A token in OpenAI roughly corresponds to 4 Latin characters, including spaces and punctuation. For example, the word "ChatGPT" consumes two tokens. The exact number of tokens depends on the specifics of OpenAI’s text processing.
If the checkbox is not selected, a new thread is created based on the message sent to the assistant, and the previous conversation context in the case is not taken into account
If the checkbox is selected, two situations are possible:
a) interaction with the AI Assistant within the case has not yet occurred → a new thread is created based on the message sent;
b) interaction with the AI Assistant within the case has already taken place → the message is added to the thread associated with the case, where the previous conversation context is taken into account.
The checkbox also impacts the usage costs of the Code Interpreter on the AI side, if this tool is used.
OpenAI's thread
In the context of working with an OpenAI assistant, a thread is an object representing the dialogue between the user and the assistant. All messages (user questions and assistant responses) within a thread are stored together, allowing the conversation context to be maintained.
Deskie adds all customer messages with the role "user" to the thread, while agent responses and automated replies triggered by rules are added with the role "assistant".
Automated replies sent by Deskie’s rules do not appear in the thread — with the "Consider the context..." option enabled, the assistant will neither see nor take them into account.
Responses from other assistants, if any are involved in the case, also do not appear in the thread.
Note: Responses added to the case through the sub-action "Received response — send to user" are technically also automated replies. Therefore, if multiple assistants are working within the same case, they will not "see" or take each other’s messages into account in the context.
A thread has a context window limit, the size of which depends on the chosen model. For example, GPT-4 Turbo supports up to 128,000 tokens (approximately 300 pages of text), while GPT-3.5 Turbo supports 16,385 tokens, which is about 24 pages of A4 text set in 12-point Times New Roman.
If the token count in a thread exceeds the limit, older or less significant messages are excluded from the context. This exclusion logic is implemented by OpenAI.
Deleting thread
Storage overflow caused by uploaded files or automatically generated vector embeddings based on them can lead to errors when working with the Assistants API. To prevent this, we have implemented the following measures on our side:
immediately after receiving the assistant’s response, the created vector store (untitled vector store) and all vector embeddings of files contained within it (vector store files) are automatically deleted;
seven days after a case is marked as "closed", the files attached to the thread, as well as the thread itself, are deleted.
Interacting with OpenAI Assistants
Sending requests to the OpenAI assistant is configured through automation rules. The action responsible for sending the request is "Send text request to AI Assistant" from the "— AI integration" category.
💰 To avoid duplicate requests and excessive token usage, this action can be specified only once within a single rule.
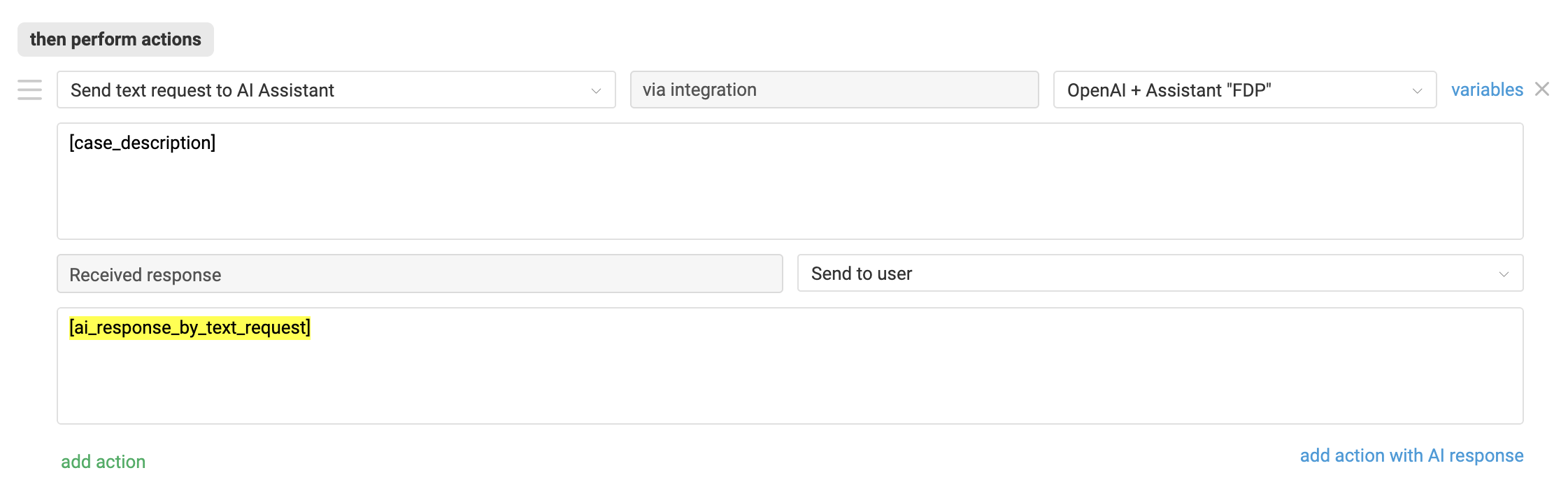
The action becomes available if an Assistant ID is specified in the OpenAI integration settings on the Deskie side. It can be used in all types of rules and allows sending a user’s or agent's message to the assistant specified in the action for processing.
You can specify the desired message using variables:
[case_description] — the first message in the case;
[last_message] — the last message in the case;
- [last_note] – the last note in the case.
The variable sends the entire message text to the assistant, including signatures or quoted content.
The assistant’s response is saved during the rule execution in the variable [ai_response_by_text_request]. It can be used in other actions within the same rule, for example, to use the AI response for:
sending it to the user;
adding a note;
writing into a request field of type "text field" or "text area".
Attachment processing
Attachments are also sent to the assistant. Whether the assistant processes the attachment depends on:
- the model used — text or multimodal;
- activated tools in settings, such as File Search and/or Code Interpreter;
- the format of the attachment.
* png, jpeg и jpg, webp, non-animated gif. More details
** processed via File search, provided the attachment format is supported.
The assistant is not always able to match data from images or other attachments with the content of files uploaded during its setup.
Assistants API configuration
Let’s take a look at the settings and tools that shape how OpenAI assistants behave and how Deskie applies them when sending requests using the action "Send text request to AI Assistant".
Official documentation for the Assistants API is available here.
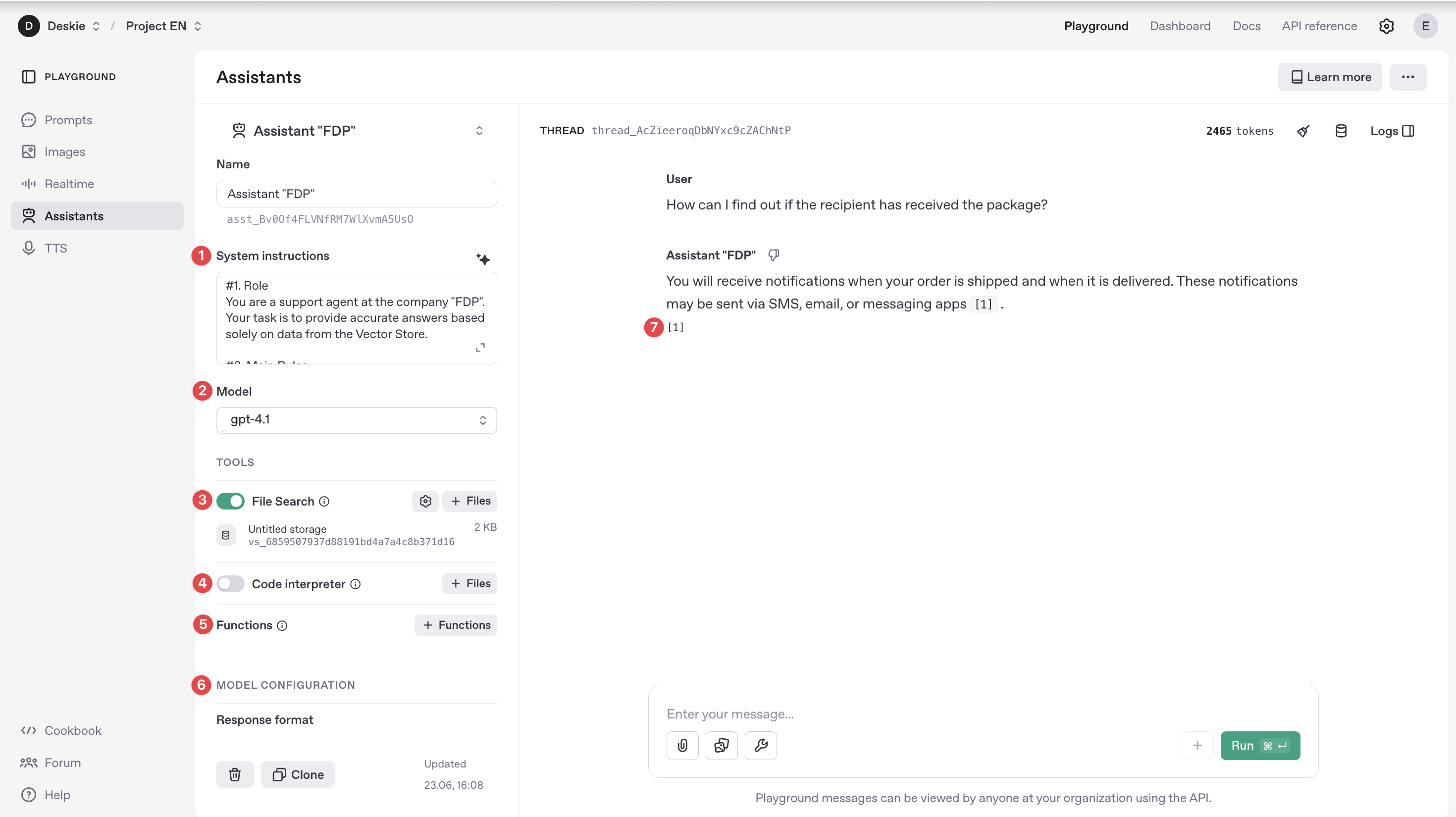
1. System instructions — define how the assistant behaves when responding to a request. Through these instructions, you can:
assign the assistant’s role — who it acts as in the dialogue: consultant, technical specialist, assistant, etc.;
specify functional capabilities — which tasks the assistant should perform and which it should not;
set the communication style — formal or informal tone, emphasis on accuracy or creativity.
💰 The more detailed the instructions, the more tokens are consumed when generating responses.
In the materials on setting up rules for interacting with the AI assistant, we provide examples of such instructions for illustrative purposes.
Requests are processed according to the instructions set in the Assistant settings in the OpenAI account.
2. Model — the OpenAI language model used by the assistant during operation.
Besides the request cost, it is important to consider the model's capabilities when choosing.
Multimodal models — such as gpt-4-turbo, gpt-4o, gpt-4o-mini, gpt-4.1, gpt-4.1-mini, gpt-4.1-nano — can analyze images with certain limitations.
Text-only models gpt-4 and gpt-3.5-turbo do not support working with images even if File Search is enabled. In gpt-4, the tool is unavailable, and gpt-3.5-turbo only considers files of supported formats, none of which are image formats. If gpt-3.5-turbo receives an image, it will return an error.
⚠️ For working with attachments and images, it is recommended to use multimodal models.
Requests are processed using the model specified in the integration settings on the Deskie side.
3. File Search — allows the assistant to use information from files uploaded during its setup.
💰 Usage cost (in addition to token charges for requests):
up to 1 GB of data per day — free;
thereafter $0.10* per additional GB;
⚠️ This tool is not available for use with the GPT-4 model. This is a limitation of the OpenAI platform itself.
This setting is taken into account by the integration on the Deskie side.
4. Code Interpreter — allows the assistant to perform calculations and analyze data.
💰 Usage cost: $0.03* per session lasting one hour.
This setting is taken into account by the integration on the Deskie side.
Billing nuances
OpenAI billing depends, among other factors, on whether the checkbox "Consider the context..." is enabled.
If the checkbox "Consider the context..." is not checked, a new thread is created based on the message sent to the assistant, and a new separately billed session for the Code Interpreter tool is initiated;
If the checkbox "Consider the context..." is checked, two situations are possible:
a) interaction with the AI Assistant within the case has not yet occurred → a separately billed one-hour session for the Code Interpreter tool is initiated;
b) interaction with the AI Assistant within the case has already occurred → a new separately billed one-hour session for the Code Interpreter tool, if used, is initiated only after one hour of interaction has passed.
5. Functions — allows the assistant to call external functions to perform tasks beyond text interaction, such as searching the internet or manipulating files.
This feature is not supported by the integration on the Deskie side.
6. Model configurations — enables adjusting the randomness and variation in response generation, as well as specifying the response format returned by the assistant.
Temperature — controls the creativity level of the model, with values from 0.01 to 2. This setting is respected by the integration on the Deskie side.
Top P — manages the diversity of the model’s responses, with values from 0.01 to 1. This setting is also respected by the integration on the Deskie side.
Response format — determines the format in which the assistant generates its response. In the OpenAI Playground, you can choose between text, Markdown, or JSON. However, Deskie sends the parameter "text" at the code level when making requests to OpenAI; the value set in the assistant’s settings is ignored.
7. [Annotations] — references to source files from the Vector Store that the assistant uses when generating responses.
Responses are displayed in the Deskie interface without indicating the sources.
______
* All prices are indicated as of the article’s publication date solely to provide comprehensive information about the integration’s operation. Deskie is not responsible for the pricing policies of third-party services and does not monitor changes in their pricing. Always verify the current costs directly with OpenAI.
Errors in the AI assistant's operation
1. AI-Side Issue
Sometimes the assistant does not return a response to a request, while all other rule actions are executed — including setting the "pending" status in the case. When this happens, Deskie adds a system note and an undeletable tag ai_error_in_rule_action to the case.

To ensure the customer does not remain without a response, these situations can be monitored through rules for updated cases using the following conditions:

2. Too many consecutive messages
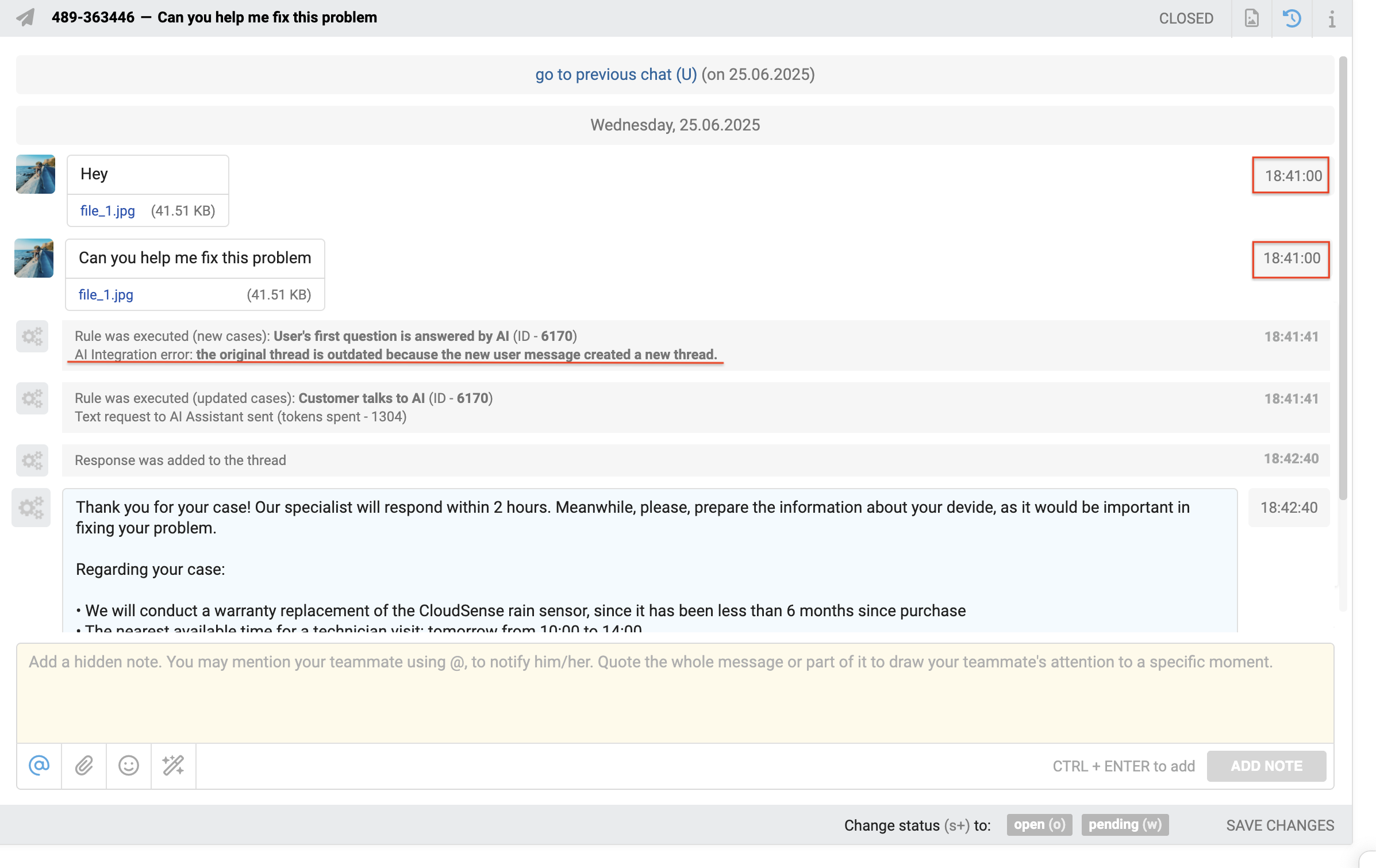
When the assistant operates in context tracking mode and the user sends several messages consecutively, a situation may arise where the previous message is still being processed, and the new one has already arrived in the same thread. In this case, Deskie:
- interrupts the current thread’s request execution;
- records the cancellation in the changelog with the note: "AI Integration error: the original thread is outdated because the new user message created a new thread";
- creates a new thread and initiates request processing for the new message there. Both the new and previous messages are transferred to the new thread to maintain the conversation sequence and full context.
Assistant's responses in statistics
In Deskie, auto-responses configured through rules are not included in statistical metrics. Therefore, for cases fully handled by the assistant, time metrics are not calculated.
SLA settings depend on the group. We recommend not setting service level parameters for groups where AI assistants handle cases.
However, if a case is transferred from the assistant to a human agent – whether the customer requested human assistance or the bot failed to respond adequately – the time metrics for such cases will start counting as if no prior responses had been made in that case.
To prevent such cases from skewing agent statistics, there are several options:
1) add special labels when transferring to a human, such as "assistant failed", "customer requested human", "AI error", etc. Using these labels, you can filter these cases during statistical analysis and consider them separately from the main flow that agents handle independently.
2) enable the option "Take into account only the time user spends while waiting for agent response" so that the time the case spends in the "waiting" status is not included in the statistics.